* intro.
- 프로그래밍을 하다보면 여러 객체를 저장하고, 꺼내 사용하는 상황이 존재함
- 이 때, 객체들을 모아 배열의 형태로 관리하게되는데 필요한 자료구조의 형태에 맞게 사용하려면 자바의 배열만으로는 효율적인 관리가 어려움
- 그래서 자바 1.2 부터는 일반적으로 알려진 자료구조의 특징과 형태를 바탕으로 객체를 효율적으로 관리할 수 있게 컬렉션 프레임워크를 지원함.
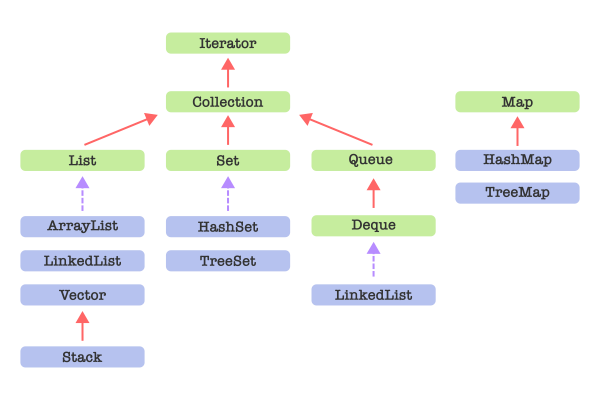
- 위 다이어그램은 초록색 박스는 인터페이스, 파란색 박스는 클래스, 빨간색 실선은 화살표 상속, 보라색 점선은 구현.
* 자료구조를 구현한 대표적인 컬렉션
- 컬렉션 프레임워크에는 많은 자료구조를 구현한 클래스들이 있다.
- 대표적인 인터페이스의 몇가지의 특징과 구현 클래스에 대해 알아보자.
* List
- List 컬렉션은 배열과 유사한 구조로 객체를 저장하게 되면 각각의 주소에 인덱스가 부여되고 그 인덱스로 검색 삭제 기능을 제공할 수 있다. 순서를 가지고, 같은 객체의 중복 저장이 가능함.
- 대표적으로 ArrayList<> , LinkedList<> , Vector 가 존재한다.
* 각각의 차이점
- ArrayList<>와 Vector는 동적 크기를 가지는 배열의 형태, LinkedList<>는 연결리스트의 형태를 가진다.
- ArrayList<>는 동기화가 되어있지 않아 멀티스레드 환경에서 명시적인 동기화가 필요.
- Vector의 경우 동기화된 자료구조로 멀티스레드 환경에서 안전하게 사용가능함.
- 연산 속도를 비교하면 "동기화" 여부의 차이로 인해 ArrayList<> 가 Vector 보다 빠르다.
* Set
- Set 컬렉션은 집합형태의 구조를 가짐.
- 중복된 데이터를 저장 할 수 없고, 순서가 존재하지 않는다.
- 저장된 데이터를 인덱스로 관리하지 않기때문에 인덱스를 매개변수로 가지는 메서드가 존재하지 않음
- 대표적으로 순서가 없는 HashSet, 순서가 존재하는 TreeSet 클래스가 존재한다.
* 중복된 데이터
- Set 에서는 객체의 hashCode로 중복을 판별한다.
- 따라서 분명 다른 객체지만 같은 hashCode를 갖는다면 같은 객체로 판별한다.
- 한마디로 == 연산자가 아닌 equals() 메서드로 비교했을 경우 true 값이 나오면 같은 객체로 판별함.
* Map
- Map 컬렉션은 Key와 Value로 구선된 Entry 객체를 저장하는 컬렉션이다.
- 이 때, Key의 객체는 중복될 수 없지만 Value의 객체는 중복될 수있다.
- Key로 객체를 관리하기 때문에 대부분의 메서드의 파라미터로 Key를 가진다.
* HashTable 과 HashMap 의 차이점.
- ArrayList와 Vecter의 차이점과 동일하다.
* TreeSet과 TreeMap
- 이름에서도 알 수 있듯 TreeSet은 Set 인터페이스를 구현한 클래스고 TreeMap 인터페이스를 구현.
- 둘은 트리 자료구조를 통해 검색기능에 특화된 클래스.
- 둘은 순서를 가지기 때문에 TreeSet에 저장되는 객체와 TreeMap의 Key에 저장되는 객체는
Comparable 인터페이스를 implements 하고 있어야 한다.
* Stack과 Queue
- Stack은 클래스로 Vector 클래스를 상속받았지만 사실상 독자적인 메서드들로 이루어져있다.
- Queue는 인터페이스로 LinkedList 클래스로 구현되어있다.
* Arrays와 Collections 클래스
- 각각 배열과 컬렉션에서 동작하는 정적 메서드로 구성된 클래스.
- 채우기, 복사, 정렬, 검색 등 각종 알고리즘 메서드를 제공.
'Computer Science > JAVA' 카테고리의 다른 글
| 디폴트 메서드, 추상 클래스와 인터페이스 (1) | 2024.11.20 |
|---|---|
| Java의 실행 엔진 (0) | 2024.11.20 |
| Java의 컴파일 과정 (0) | 2024.11.20 |
| Class Loader에 대해서 (0) | 2024.11.19 |
| 동기 Async 와 비동기 ASync (1) | 2024.11.18 |
